Beanstalk Messaging Queue
When researching about Messaging Queue softwares, I found a very useful blog at http://nubyonrails.com/articles/about-this-blog-beanstalk-messaging-queue, so I decide to re-post here for future reference as well as for anyone who is interested in.
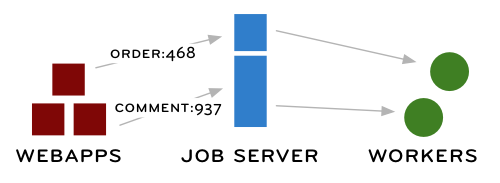
Web developers often get into the rut of thinking about every programming task in the context of a request and a response. A request comes for a URL, content is retrieved and converted into useful output, then sent back to the client. Lather, rinse, repeat.
But there are also other types of programming tasks that don’t fit into that cycle. What about tasks that need to happen
- at a certain time of day?
- after the response has been sent back to the client?
- at some point in the future after another event has happened?
Here are some examples from my applications:
- Time of day: Log parsing, sales reports
- After a response: State-based payment transactions with other servers that need to complete before moving to the next stage, spam-filtering of blog comments against an external API server
- In the future: A task to checkup on an order to make sure it has been delivered within an hour after purchase
Previously, I approached most of these problems with a few rake tasks and a cron job that ran every minute. While it worked, it wasn’t as fast as it could be and felt a bit hackish (a delay of even one minute is too slow sometimes).
For a while, I’ve wanted to learn more about messaging queues. I love tools that don’t only enhance something I’m already doing, but completely change the way I think about designing an application.
The Problem

Queues are a great tool for some tasks. Having the ability to send something off to a queue can solve some of these problems and also give you another option for optimizing the speed of normal HTTP responses, too.
Initially, I decided to try this out on my blog. I use the remote Akismet service to check comments for SPAM. To be honest, Akismet is usually fast enough that I could make the call in the middle of the request without any problems, but I wanted to try out the message queue before deploying a similar idea atPeepCode.com.
In the application, every comment starts out with a received state (usingacts_as_state_machine). The Comment controller will fire off a job and a separate worker will handle the SPAM-checking so the web process can respond quickly and get back to work responding to other web requests.

Messaging Servers
There’s been some fresh activity even just over the last few weeks in this area. Ara Howard compared some of these recently. I haven’t evaluated all of these packages, but here are a few I’ve looked at:
| Product | Features | Drawbacks |
| beanstalkd | Fast, simple, designed to mirror the style of memcached. Rails plugin available, or usable with a simple Ruby-based API. Server written in C, but is very easy to install. | Memory only…jobs are not persistent. New, so the internal protocol may change. Workers may be difficult to manage. |
| bj | Rails plugin. Self-spawning. | Can only send shell commands. Jobs start a full copy of your Rails app on every execution. |
| BackgroundRB | Ruby-based. Can be polled for incremental feedback on the progress of a job. Recently rewritten. | |
| Amazon SQS | Runs on Amazon’s cluster, so it can handle a ton of traffic. | Operated by Amazon, so it doesn’t run locally. Not open source. |
| Apache ActiveMQ | Well-known. Persistent. | Requires several installation steps and database tables. |
| ActiveMessaging | Rails plugin. Works with ActiveMQ and others. | Requires external job server. |
| BBQ | Nothing to install…involves only a single line of code! | Doesn’t work on Windows NT4. |
For this blog, I chose to try beanstalkd.
- It is not persistent and exists only in memory, but my application usesacts_as_state_machine, so I can see if any job failed to run.
- It’s very fast and was made to help with scaling a multi-million person Facebook app running on Rails.
- There are some nice features like delayed jobs. Put a job in the queue and it can show up immediately, or after a period of time.
- There is a Ruby client and a Rails plugin.
Installation
Download the beanstalkd server and compile it. Use make for production ormake debug for your development copy (to print out extra messages as it’s working). There’s no task to install it, but you can just copy the executable to/usr/local/bin.
Start the server (use -h to see other possible arguments):
% beanstalkd
beanstalkd: net.c:90 in unbrake: releasing the brakesInstall the beanstalk-client gem. For this blog, I chose to use the gem directly.
sudo gem install beanstalk-clientIn merb_init.rb (or config/environment.rb), I setup a connection to the beanstalk server.
BEANSTALK = Beanstalk::Pool.new(['localhost:11300'])In the Comments controller, I put a comment job into the queue, using the id of the new comment.
# Comments controller
def create
@comment = Comment.new(params[:comment])
if @comment.save
BEANSTALK.yput({:type => "comment", :id => @comment.id}) rescue nil
# Then redirect and returnThe yput method uses YAML to serialize any arguments and put them into the queue.
Finally, I wrote a rake task to function as the worker.
loop do
job = BEANSTALK.reserve
# ybody deserializes the job
job_hash = job.ybody
case job_hash[:type]
when "comment"
if Comment.check_for_spam(job_hash[:id])
job.delete
else
job.bury
end
else
puts "Don't know what type of job this is: #{job_hash.inspect}"
end
endIn the future, I’d like to look into using daemonize or some other method for running the worker. In the meantime, I’m using god to start the worker and keep it running.
The details are a bit of a hack, but here is the god.conf if you want to try it. The benefit is that god keeps the worker running and daemonizes it so it runs in the background.
sudo god start -c /var/www/apps/mysite.com/current/config/god.confI can also call god restart beanstalk-worker from a Capistrano task to restart it and keep the code fresh.
Results
In practice over the past week or so, this has been very reliable. The message passing is so fast that sometimes it actually runs the SPAM check before the redirect back to the article page is done!
It was fairly simple to setup and now provides me with a tool for accomplishing tasks that don’t need to be completed in the scope of an HTTP response.
Tips
- Keep queue items small. Put an
idand some kind of identifier, not an entire model. I could have stored the entire contents of the comment, but it’s more efficient to just pass theidof the comment and let the worker get a current copy from the database. - Keep worker code small: By calling methods on the
Commentmodel, I keep the code in one place (even though it will be executed in different contexts).
Future
Now that it’s working smoothly here, I hope to use it on PeepCode. Some possibilities:
- Google Checkout pings: I need to ping Google after their server notifies me that an order has passed a security check. It can’t be done in a model callback because I need to complete an XML response to Google before moving to the next state. This kind of setup will be perfect since I can put a job in the queue and give it a small delay before it runs.
- Order followup in the future: I currently have some cron jobs that check recent orders to make sure they have completed succesfully. It would be easy to use this system to put several jobs in the queue after an order is placed. They would run after 30 minutes, 1 hour, or 2 hours. The job would send a notification if the order has not been completed, or ignore it if it’s done by the time the job runs.
Finally, PeepCode in Italiano!
Ryan Daigle’s Rails 2 PDF is now available in Italiano as well as English andEspañol.
