Scaling a PHP MySQL Web Application, Part 2
This article was original written by By Eli White and was published at http://www.oracle.com/technetwork/articles/dsl/white-php-part2-355138.html. This includes tips for scaling your PHP-MySQL Web app based on real-world experiences at Digg, TripAdvisor, and other high-traffic sites.
In Part 1 of this article, I explained the basic steps to move your application from a single server to a scalable solution for both PHP andMySQL. While most Web applications will never need to expand beyond the concepts presented in that article, eventually you may find yourself in a situation where the basic steps aren’t enough.
Here are some more advanced topics on how you might change your setup to support additional throughput, isolate “concerns” better, and take your scalability to the next level.
MySQL Database Pooling
Database pooling is one fairly simple technique that allows for greater “isolation of concerns.” . This concept involves having a group of database slaves virtually separated into multiple pools. Each pool has a specific classes of queries sent to it. Using a basic blog as an example case, we might end up with a pool distribution like this:

Figure 1 Database pooling
Now the obvious question at this point is: Why? Given that all the slaves in the above setup are identical, then why would you consider doing this?
The main reason is to isolate areas of high database load. Basically, you decide what queries are OK to perform more slowly. In this example you see that we’ve set aside just two slaves for batch processes. Typically if you have any batch processes that need to run in the background you aren’t worried about how fast they run. Whether it takes five seconds, or five minutes, doesn’t matter. So it’s OK for the batch processes to have fewer resources, thereby leaving more for the rest of the application. But perhaps more important, the kinds of queries you may typically do when performing large batch processes (and the reason they are not done in real time in the first place) can be rather large and resource intensive.
By isolating these processes off to their own database slaves, your batch processes firing off won’t actually affect the apparent performance of your Web application. (It’s amazing how many Websites get slower just after midnight when everyone decides to run cron jobs to background-process data.) Isolate that pain and your Website performs better. You’ve now created selective scalability.
The same concept can apply to other aspects of your application as well. If you think about a typical blog, the homepage only shows a list of posts. Any comments to those posts are displayed only on a permalink page. Retrieving those comments for any given post can be a potentially painful process, given there can be any number of them. It’s further complicated if the site allows threaded comments because finding and assembling those threads can be intense.
Therein lays the benefit of database pooling. It’s usually more important to have your homepage load extremely fast. The permalink pages with comments can be slower. By the time someone is going to load the full post, they’ve committed and are willing to wait a little longer. Therefore, if you isolate a set of slaves (four in the example above) to be specific to queries about comments, you can leave the larger pool of ‘primary’ slaves to be used when generating homepages. Again you’ve isolated load and created selective scalability. Your comment and permalink pages might become slower under heavy load, but homepage generation will always be fast.
One way that you can apply scalability techniques to this pool model is to allow on the fly changes to your pool distribution. If you have a particular permalink that is extremely popular for some reason, you could move slaves from the primary pool to the comments pool to help it out. By isolating load, you’ve managed to give yourself more flexibility. You can add slaves to any pool, move them between pools, and in the end dial-in the performance that you need at your current traffic level.
There’s one additional benefit that you get from MySQL database pooling, which is a much higher hit rate on your query cache. MySQL (and most database systems) have a query cache built into them. This cache holds the results of recent queries. If the same query is re-executed, the cached results can be returned quickly.
If you have 20 database slaves and execute the same query twice in a row, you only have a 1/20th chance of hitting the same slave and getting a cached result. But by sending certain classes of queries to a smaller set of servers you can drastically increase the chance of a cache hit and get greater performance.
You will need to handle database pooling within your code – a natural extension of the basic load balancing code in Part 1. Let’s look at how we might extend that code to handle arbitrary database pools:
<?php
class DB {
// Configuration information:
private static $user = 'testUser';
private static $pass = 'testPass';
private static $config = array(
'write' =>
array('mysql:dbname=MyDB;host=10.1.2.3'),
'primary' =>
array('mysql:dbname=MyDB;host=10.1.2.7',
'mysql:dbname=MyDB;host=10.1.2.8',
'mysql:dbname=MyDB;host=10.1.2.9'),
'batch' =>
array('mysql:dbname=MyDB;host=10.1.2.12'),
'comments' =>
array('mysql:dbname=MyDB;host=10.1.2.27',
'mysql:dbname=MyDB;host=10.1.2.28'),
);
// Static method to return a database connection to a certain pool
public static function getConnection($pool) {
// Make a copy of the server array, to modify as we go:
$servers = self::$config[$pool];
$connection = false;
// Keep trying to make a connection:
while (!$connection && count($servers)) {
$key = array_rand($servers);
try {
$connection = new PDO($servers[$key],
self::$user, self::$pass);
} catch (PDOException $e) {}
if (!$connection) {
// Couldn’t connect to this server, so remove it:
unset($servers[$key]);
}
}
// If we never connected to any database, throw an exception:
if (!$connection) {
throw new Exception("Failed Pool: {$pool}");
}
return $connection;
}
}
// Do something Comment related
$comments = DB::getConnection('comments');
. . .
?>As you can see, very few changes were needed. This of course was purposeful. Knowing that pooling was desirable, the original code was formulated to be extensible. Any code designed to randomly select from a “pool” of read slaves in the first place should be able to be extended to simply understand that there are multiple pools to choose from.
Of course, the comments in Part 1 apply to this code as well: You will probably want to encapsulate your logic within a greater database abstraction layer, add better error reporting, and perhaps extend the features offered.
MySQL Sharding
At this point, we’ve covered all the truly easy steps towards scalability. Hopefully by this point, you’ve found solutions that work. Why? Because the next steps can be very painful from a coding perspective. I know this personally for they are steps that we had to take when I worked at Digg.
If you need to scale farther, it’s usually for one of a couple reasons. All of them reflect various pain points or bottlenecks in your code. It might be because your tables have gotten gigantic, with tens or hundreds of millions of rows of data in them, and your queries are simply unable to complete quickly. It could be that your master database is overwhelmed with write traffic. Perhaps you have some other pain point which is similar to these situations.
One possible solution is to shard your database. Sharding is the common-use term for a tactic practiced by many of the well known Web 2.0 sites, although many other people use the term partitioning. Partitioning is in fact a way to split individual tables into multiple parts within one machine. MySQL has support for some forms of this where each partition has the same table schema, which makes the data division transparent to PHP applications.
So what is sharding? The simplest definition I can come up with is just this: “Breaking your tables or databases into pieces.”
Really, that’s it. You are taking everything you have and breaking it into smaller shards of data. For example, you could move last year’s infrequently accessed blog comments to a separate database. This allows you to scale more easily and to have faster response times since most queries look at less data. It can also help you scale write-throughput by breaking out into using multiple masters. This comes at a cost, though, on the programming side. You need to handle much more of your data logic within PHP, whether that is the need to access multiple tables to get the same data, or to simulate joins that you can no longer do in SQL.
Before we get into discussing that various forms of sharding and their benefits (plus drawbacks) there is something I should mention. This entire section addresses doing manual sharding and controlling it within your PHP code. Being a programmer myself, I like having that control as it gives me the ultimate flexibility. Also in the past, it’s been the solution that in the end won out. There are some forms of sharding that MySQL can do for you via features such as federation and clustering. I do recommend that you explore those features to see if they might be able to help you without taking the extra PHP load. For now, let’s discuss the various forms of manual sharding.
Vertical Sharding
Vertical sharding is the practice of moving various columns of a table into different tables. (Many people don’t even think of this tactic as sharding per se but simply as good-old database design via normalizing tables.) There are various methodologies that can help here, primarily based around moving rarely used or often-empty columns into an auxiliary table. This often keeps the important data that you reference in one smaller table. By having this smaller, narrower table, queries can execute faster and there is a greater chance that the entire table might fit into memory.
A good rule of thumb often is to move any data that is never used in a WHERE clause into an auxiliary table. The idea is that you want the primary table that you perform queries against to be as small and efficient as possible. You can later read the data from the auxiliary table after you know exactly which rows you need.
An example might be a users table. You may have columns in that table that refer to items you want to keep but rarely use. Perhaps their full name or their address, which you keep for reference about the user but you never display on the Website nor search based upon it. Moving that data out of the primary table can therefore help.
The original table might look like:

A vertically sharded version of this would then look like:

It should be noted that vertical sharding is usually performed on the same database server. You aren’t typically moving the auxiliary table to another server in an attempt to save space, but you are breaking a large table up and making the primary query table much more efficient. Once you’ve found the row(s) of information in Users that you are interested in, you can get the extra information – if needed – by highly efficient ID lookups on the UsersExtra.
Manual Horizontal Sharding
Now if vertical sharding is breaking up the columns of a table into additional tables, horizontal sharding is breaking the rows in a table into different tables. At this point, the sole goal behind doing this is to take a table that has become so long to be unwieldy (millions upon millions of rows) and to break it into usable chunks.
If you are doing this manually by spreading the shared tables across multiple databases, it is going to have an effect on your code base. Instead of being able to look in one location for certain data, you will need to look in multiple tables. The trick with doing this in a way to have minimal impact on your code is to make sure that the methodology used to break your table up matches how the data will be accessed in the code.
There are numerous common ways to manually do horizontal sharding. One could be range-based, wherein the first million row IDs are in the first table, the next million row IDs in table two, and so on. This can work fine as long as you always know that you are going to know the ID of the row you will want, and therefore can have logic to pick the right table. A drawback of this method is that you’ll also need to create tables as thresholds are crossed. It means either building table creation code into your application, or always making sure that you have a “spare” table, and processes to alert you when it starts being used.
Another common solution that obviates needing to make new tables on-the-fly is to have interlaced rows. This is the approach, for example, of using the modulus function on your row numbers, and evenly dividing them out into a pre-set number of tables. So if you did this with three tables, the first row would be in table 1, the second row in table 2, the third in table 3, and then the fourth row would be in table 1.
This methodology still requires you to know the ID in order to access the data, but now removes the concern of ever needing a new table. At the same time, it comes with a cost: If you choose to break into three tables, and eventually those tables get too large, you will come to a painful point of needing to redistribute your data yet again.
Beyond the ID based sharding, some of the best sharding techniques cue off different data points that closely match how the data will be accessed. For example, if writing a typical blog or news application, you typically will always know the date of any post that you are trying to access. Most blog permalinks store the month and year within them such as: http://myblog.example.com/2011/02/Post. This means that any time that you are going to read in a post, you already know the year and month . Therefore, you could partition the database based upon the date, making a separate table for each year or perhaps a separate table for each year/month combination.
This does mean that you need to understand the logic for other access needs as well. On the homepage of your Website, you might want to list the last five posts. To do this now, you might need to access two tables (or more). You’d first attempt to read in five posts from the current year/month table, and if you didn’t find all five, start iterating back in time, querying each table in turn until you’ve found all that you need.
In this date-based setup, you do still need to make new tables on the fly, or have them pre-made and waiting. At least in this situation, you know exactly when you will need new tables, and could even have them pre-made for the next few years, or a cronjob that makes them on a set schedule.
Other data columns can be used for partitioning as well. Let’s explore another possibility using the data we used for horizontal partitioning. In the case of this Users table, we might realize that in our application we will always know the username when we go to access a specific user’s information, perhaps because they have to login first and provide it to us. Therefore, we could shard the table based upon the usernames, putting different sections of the alphabet into different tables. A simple two-table shard could therefore look like:
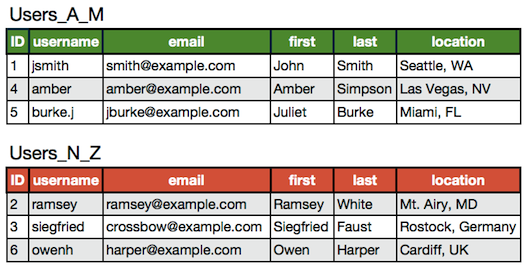
This horizontal sharding can be used within the same database just to make tables more manageable. However most often this tactic begins to see use when you have so much data that you need to start breaking it out into multiple databases. This could be either for storage concerns or throughput. In this case you can easily, once sharded, move each table onto their own master with their own slave pools, increasing not only your read throughput, but your write throughput as well.
Application-Level Sharding
At this point we’ve discussed the ideas of breaking your tables up both by rows and by columns. The next step, which I will refer to asapplication-level sharding, is explicitly taking tables from your database and moving them onto different servers (different master/slave setups).
The sole reason for this is to expand your write throughput and to reduce overall load on the servers by isolating queries. This of course comes with – as all sharding does – the pain of rewriting your code to understand where the data is stored, and how to access it now that you’ve broken it up.
The interesting thing about application-level sharding is that if you’ve already implemented “pool” code (as shown previously), that exact same code can be used to access application shards as well. You just need to make a separate pool for each master and make pools for each set of shard slaves. The code needs to ask for a connection to the right pool for the shard that holds your data. The only real difference from before is that you have to be extra careful with your queries, since each pool isn’t a copy of the same data.
One of the best tactics when looking to break your database up is to base it upon a natural separation of how your application accesses data. Keep related tables together on the same server so that you don’t lose the ability to quickly access similar data through the same connection (and perhaps even keep the ability to do joins across those related tables).
For example, let’s look at this typical blog database structure and how we might shard it:

Figure 3 Keeping related tables together
As you can see, we’ve broken this table into two application-based shards. One contains both the Users and Profiles tables. The other contains the blog Entries and Comments tables. The related data is kept together. With one database connection you can still read both core user information as well as their profiles. With another connection you can read in the blog entries and their associated comments and potentially even join between those tables if needed.
Conclusion
In the end, all of these techniques – pooling and various forms of sharding – can be applied to your system to help it scale beyond its current limitations. They should all be used sparingly and only when needed.
While setting your system up for MySQL database pooling is actually fairly easy and painless, sharding is a different matter, and in my opinion it should only be attempted once you have no other options available to you. Every implementation of sharding requires additional coding work. The logic used to conceptually break your database or tables up needs to be translated into code. You are left without the ability to do database joins or can do them only in a limited fashion. You can be left without the ability to do single queries that search through all of your data. Plus you have to encapsulate all of your database access behind more abstraction layers that understand the logic of where the data actually exists now, so that you can change it in the future again if needed.
For that reason, only do the parts that directly match your own application’s needs and infrastructure. It’s a step that a MySQL-powered Website may need to take when data or traffic levels rise beyond manageable sizes. But it is not a step to be taken lightly.