Scaling a PHP MySQL Web Application, Part 1

This article was original written by By Eli White and was published at http://www.oracle.com/technetwork/articles/dsl/white-php-part1-355135.html. This includes tips for scaling your PHP-MySQL Web app based on real-world experiences at Digg, TripAdvisor, and other high-traffic sites.
Creating a Web application – actually writing the core code – is often the initial focus of a project. It’s fun, it’s exciting, and it’s what you are driven to do at that time. Hopefully however, there always comes a time when your application starts to take higher traffic than originally expected. This is the point where people often start thinking about how to scale their Website.
Ideally, you should be thinking about how your application is going to scale from the moment you first write code. Now, that is not to say that you should spend a lot of effort in your early development process targeted at an unknown future. Who knows what will happen and if your application will ever hit the traffic levels that require a scalability effort? But hopefully the most important lesson you can learn here is to understand what you will need to do to scale in the future. By knowing this, you can do only what you need at each phase of your project without “coding yourself into a corner”, ending up in a situation where it’s hard to take the next scalability step.
I’ve worked for a number of companies and projects that over time had to deal with massive levels of Web traffic. These include Digg, TripAdvisor, and the Hubble Space Telescope project. In this two-part article I will share some of the lessons learned, and take you step by step through a standard process of scaling your application.
Performance vs. Scalability
Before we go much further, we should discuss the differences (and similarities) between performance and scalability.
Performance, in the context of a Web application, is how fast you can serve data (pages) to the end user. When people talk about increasing the performance of their application, they are talking typically about making it take 300ms instead of 500ms to generate the content.
Scalability, in contrast, is the quality that enables your application to grow as your traffic grows. A scalable application is one that theoretically, no matter how much traffic is sent toward it, can have capacity added to handle that traffic.
Scalability and performance obviously are interrelated . As you increase the performance of an application, it requires fewer resources to scale it, making scaling easier. Similarly, you can’t really call an application scalable if it requires one Web server per user for adequate performance, as it would be untenable for you to provide that.
PHP Tuning
One thing that you should look at first is any low-hanging fruit within your Web server and PHP setup. There are some very easy things you can look into that can immediately increase performance and perhaps relieve the need to scale at this point in time completely, or at least make it easier.
The first of these is installing an opcode cache. PHP is a scripting language, and therefore recompiles the code upon every request. Installing an opcode cache into your Web server can circumvent this limitation. Think of an opcode cache as sitting between PHP and the server machine; after a PHP script is first compiled, the opcode cache remembers the compiled version and future requests simply pull the already compiled version.
There are numerous opcode caches available. Zend Server comes with one built-in and Microsoft provides one for Windows machines called ‘WinCache’. One of the most popular ones is an open source product called APC. Installing any of these products is very straightforward, and doing so will give you immediate and measurable performance gains.
The next step that you should evaluate is if you can remove the dynamic nature of any of your Web pages. Often Web applications will have pages that are being generated by PHP but that actually rarely change. Examples might be an FAQ page, or a press release. Caching the generation of these pages and serving the cached content so that PHP doesn’t need to do any work can save many CPU cycles.
There are multiple ways to approach this task. One of them is to actually pre-generate HTML pages from your PHP and let the HTML pages be directly served to the end users. This could be done as a nightly process perhaps, so that any updates to the Web pages do in fact go live eventually, but on a delayed schedule. Implementing this can be as simple as running your PHP scripts from the command line, piping their output to .html files, and then changing links in your application.
However there is an even easier approach to this that requires less effort: implementing an on-the-fly cache. Basically your entire script output is captured into a buffer saved to the filesystem, into memory/cache, or into the database, etc. All future requests for that same script just read from the cached copy. Some templating systems (such as Smarty) automatically do this for you, and there are some nice drop-in packages that can handle this for you as well (such as jpcache).
The simplest version of this is something fairly easy to write yourself: the following code injected at the top of your typical PHP page will handle this for you (obviously replace the timeout and cache directories to meet your needs). Encapsulate this into a single library function, and you could cache pages easily as needed. As this exists, it blindly caches pages based only upon the URL and GET parameters. If the page changes based upon a session, POST data, or cookies, you’d have to add those into the uniqueness of the filename created.
<?php
$timeout = 3600; // One Hour
$file = '/tmp/cache/' . md5($_SERVER['REQUEST_URI']);
if (file_exists($file) && (filemtime($file) + $timeout) > time()) {
// Output the existing file to the user
readfile($file);
exit();
} else {
// Setup saving and let the page execute:
ob_start();
register_shutdown_function(function () use ($file) {
$content = ob_get_flush();
file_put_contents($file, $content);
});
}
?>Load Balancing
When creating Web applications, everyone starts with a single server that handles everything. That’s perfectly fine, and in fact how things should usually be done. One of the first steps you will need to take to begin scaling your Web application to handle more traffic is to have multiple Web servers handling the requests. PHP is especially well suited to horizontal scaling in this manner by simply adding more Web servers as needed. This is handled via load balancing, which, fundamentally, is simply the concept of having a central point where all requests arrive and then handing the requests off to various Web servers.

Figure 1 Load balancing
There are numerous options for handling your load balancing operationally. For the most part they fall into three different categories.
The first are the software balancers. This is software that you can install on a standard machine (usually Linux based) and that will handle all the load balancing for you. Each software balancer also comes with its own extra features such as built in page output caching, gzip compression, and more. Most of the popular options in this category are actually multipurpose software / Web servers themselves that happen to have a reverse proxy mode you can enable to do load balancing. These include Apache itself, Nginx, andSquid. There is also some smaller dedicated load balancing software such as Perlbal. You can even do a very simple version of this in your DNS server just by using DNS rotation so that every DNS request responds with a different IP address, although that is obviously not very flexible.
The second category is the hardware balancers. These are physical machines that you can buy, designed to handle very large traffic levels and with custom software built into them. Two of the better-known versions of this are the Citrix Netscaler and the F5 BigIP. The hardware solutions often provider many custom benefits, and act as firewalls and security barriers as well.
The final classification is a new one referring specifically to cloud-based solutions. When hosting on cloud providers you obviously don’t have the ability to install a hardware-based solution, restricting you to the software-only solutions. But most cloud providers also have their own built-in mechanisms for handling load balancing across their instances. In some cases these are less flexible, but are much easier to setup and maintain.
In the end, all of the solutions, whether software or hardware, all typically offer many of the same features. The ability to manipulate or cache the data as it comes across, the ability to load balance either by random selection or through watching health meters on the various sub machines, and much more. I would recommend that you explore what options exist for your hosting environment and simply find which one serves your situation the best. There are very good setup guides for any solution you would choose online that cover all the basics.
Load Balancing Preparation
As mentioned earlier in this article, it’s important to only do what you need to but to be mentally ready to take the next steps. Rarely will you ever setup load balancing when you are first building your application but you should keep a few things in mind to make sure that you don’t preclude yourself from doing it later.
First of all, if you are using any kind of local memory caching solution (such as the one provided by APC) you need to write your code without assuming that you’ll only have a single cache. Once you have multiple servers, data you store on one machine is only accessible from that machine.
Similarly a common pitfall is assuming a single file system. PHP Sessions can’t be stored in the file system anymore once you are using multiple servers, and you need to find another solution for them (such as a database). I’ve also seen code that stored uploaded files and expected to read them back later. You therefore need to assume that you shouldn’t store anything on the file system.
Now with all that said, you can still use the techniques listed previously if you feel there is a strong need for the rapid development of your initial application. What’s important is that you encapsulate any ‘single machine’ dependant code. Make sure that it’s in a single function, or at least within a class. Then, when the time comes to move to load balancing, there’s only one place you need to update to a new solution.
MySQL Master-Slave Replication
At this point you’ve hopefully got your Web server setup to be scaling wonderfully. Now most Web applications find their next bottleneck: the database itself. MySQL is very powerful but eventually you will run into the same problem as with Web servers where one simply isn’t enough. MySQL comes with a built-in solution for this called master-slave replication.
In a master-slave setup, you will have one server that acts as the master, the true repository of the data. You then setup another MySQL server, configuring it as the slave of the master. All actions that take place on the master are replayed on the slave.
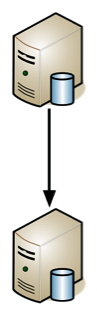
Figure 2 Master-slave setup
Once configured in this manner, then you make sure that your code talks to the ‘proper’ database depending upon the action you need to take. Any time you need to change data on the server (update, delete and insert commands), you connect to the Master. For read access, you connect to the slave instead. This could be as straight forward as something like:
<?php
$master = new PDO('mysql:dbname=mydb;host=127.0.0.2', $user, $pass);
$master->exec('update users set posts += 1');
$slave = new PDO('mysql:dbname=mydb;host=127.0.0.3', $user, $pass);
$results = $slave->query('select id from posts where user_id = 42');
?>There are two benefits to taking this approach for scalability. First of all, you’ve managed to separate the load on the database into two parts. So off the bat you’ve reduced the load on each server. Now that’s typically not going to be an even split; ost Web applications are very read heavy, and so the slave will be taking more of the load. But that brings us to the second point: isolation. At this point you’ve isolated two distinct types of load, the write and read. This will allow you greater flexibility in taking the next scalability steps.
Slave Lag
There is really only one main pitfall when doing this (other than ensuring you are always talking to the right MySQL database), and that is slave lag. A database slave doesn’t instantly have the same data that the master has. As mentioned, any commands that change the database are essentially re-played on the slaves. That means however that there is a (hopefully very short) period of time after an update is issued on the master before it will be reflected on the slave. Typically this is in the order of milliseconds but if your servers are overloaded, slaves can get much farther behind.
The main change that this makes to your code is that you can’t write something to the master and then immediately attempt to read it back. This otherwise is somewhat common practice if you are using SQL math, have default values, or triggers in place. After issuing a write command your code may not know the value on the server and therefore want to read it in to continue processing. A common example would be:
<?php
$master->exec('update users set posts += 1');
$results = $slave->query('select posts from users');
?>Even with the fastest setup possible, this will not give expected results. The update will not have been re-played against the slave before the query is executed and you will get the wrong count of posts. In cases like this therefore, you need to find workarounds. In the absolute worst case you can query the master for this data, though that defeats the purpose of “isolation of concerns”. The better solution is to find a way to “approximate” the data. For example, in an example where you are showing a user adding a new post, just read in the number of posts first and manually add one to it before displaying the value back to the user. If it happens to be incorrect because multiple posts were being added at the same time, it’s only for that one Web page. The database is correct for other users reading the value.
Multiple MySQL Slaves
At this point the next logical step is to expand your MySQL database capacity horizontally by adding in additional slaves. One master database can feed any number of slave machines – within some extreme limits. While few systems will experience this you do have theoretical limits where the single master can’t keep up with the multitude of slaves.
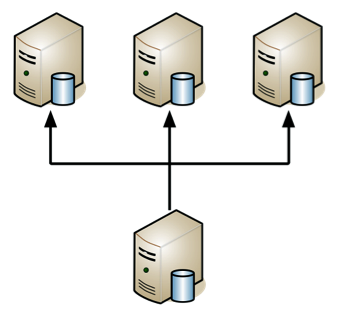
Figure 3 Multiple MySQL slaves
I explained previously that one of the benefits of using master-slave was the isolation of concerns. Combine this with the fact that most Web applications are read-heavy because they add data rarely compared with the need to access data to generate every page. This means that usually your scalability concern is read access. That’s exactly what adding more slaves gives you. Each additional slave you add increases your database capacity just like adding more Web servers does for PHP.
Now this leaves you with a potential complication. How do you determine to which database to connect? When you had just a single database that decision was easy. Even when you had a single slave it was easy. But now to properly balance the database load you need to connect to a number of different servers.
There are two main solutions that people deploy in order to handle this.The first is to have a dedicated MySQL database slave for each Web server that you have. This is one of the simplest solutions and commonly deployed for that reason. You can envision this as looking something like this:

Figure 4 Dedicated database slave for each Web server
In this diagram you see a load balancer with three Web servers behind it. Each Web server is speaking to its own database slave which in turn gets data from a single master. The decision for your Web servers as to which database to access is very simple as it’s no different than in a single-slave situation – you just need to configure each Web server to connect to a different database as its slave.
However in practice when this solution is deployed it’s often taken one step further: one single machine that acts as both Web server and database slave. This simplifies matters greatly as connections to your slave are simply to ‘localhost’ and balancing is therefore built in.
There is a large drawback to taking this simple approach however, and it causes me to always shy away from it: You end up tying the scalability of your Web servers to your MySQL database slaves. Again, isolation of concerns is a big thing for scaling. Quite often the scaling needs of your Web servers and of your database slaves are mutually independent. Your application might need the power of only three Web servers, but need 20 database slaves if it’s very database intensive. Or you might need three database slaves and 20 Web servers if it’s PHP- and logic-intensive. By tying the two together, you are forced to add both a new Web server and a new database slave at the same time. This also means that you are adding to the maintenance overhead.
Combining Web server and database slave onto the same machine also means you are over utilizing resources on each machine. Plus you can’t acquire specific hardware that matches the needs of each service. Typically the requirements for database machines (large and fast I/O) aren’t the same as for your PHP slaves (fast CPU).
The solution to this is to sever the relationship between Web servers and MySQL database slaves, and randomize connections between them. Literally in this case you would have each request that comes to a Web server randomly (or with an algorithm of your choice) select a different database slave to which to connect.
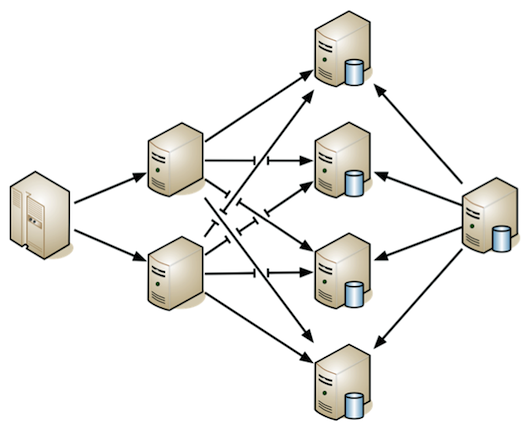
Figure 5 Randomizing the connections between Web servers and database slaves
This approach enables the ability to scale your Web servers and database slaves independently. It can even enable smart algorithms that figure out which slave to which to connect, based upon whatever logic works best for your application.
There’s also another great benefit that we’ve not talked about yet: stability. Via randomized connections, it’s possible for a database slave to go down and for your application to not care, as it will just pick another slave to connect to instead.
Usually it’s your job to write code within your application that picks which database to which to connect. There are some ways to avoid this task, such as putting all the slaves behind a load balancer and connecting to it. But having the logic in your PHP code gives you, as a programmer, the greatest flexibility in the future. Following is an example of some basic database selection code that accomplishes this task:
<?php
class DB {
// Configuration information:
private static $user = 'testUser';
private static $pass = 'testPass';
private static $config = array(
'write' =>
array('mysql:dbname=MyDB;host=10.1.2.3'),
'read' =>
array('mysql:dbname=MyDB;host=10.1.2.7',
'mysql:dbname=MyDB;host=10.1.2.8',
'mysql:dbname=MyDB;host=10.1.2.9')
);
// Static method to return a database connection:
public static function getConnection($server) {
// First make a copy of the server array so we can modify it
$servers = self::$config[$server];
$connection = false;
// Keep trying to make a connection:
while (!$connection && count($servers)) {
$key = array_rand($servers);
try {
$connection = new PDO($servers[$key],
self::$user, self::$pass);
} catch (PDOException $e) {}
if (!$connection) {
// We couldn't connect. Remove this server:
unset($servers[$key]);
}
}
// If we never connected to any database, throw an exception:
if (!$connection) {
throw new Exception("Failed: {$server} database");
}
return $connection;
}
}
// Do some work
$read = DB::getConnection('read');
$write = DB::getConnection('write');
. . .
?>Of course there are numerous enhancements you may want (and should) make to the above code before it could be used in production. You probably want to log the individual database connection failures. You shouldn’t store your configuration as static class variables because you can’t change your configuration without code changes. Plus, in this setup, all servers are treated as equals. It can be worthwhile to add the idea of server ‘weighting’ so that some servers could be assigned less traffic than others. In the end you’ll most likely want to encapsulate this logic into a greater database abstraction class that gives you even more flexibility.
Conclusion
By following the steps in this article you should be well on your way to a scalable architecture for your PHP application. In the end, there really is no single solution, no magic bullet. It’s the same reason that there isn’t just one application solution or one framework. Every application will have different bottlenecks and different scaling problems that need solved.
Hello Conan, I just read your article about ‘Scaling a PHP MySQL Web Application.’ It provides an amazing solution for scaling large applications and keeping them up to date.